Software Testing Policy and Strategy
List of abbreviations
ABBR |
MEANING |
|---|---|
AIV |
Assembly, Integration and Verification |
BDD |
Behaviour Driven Development |
CD |
Continuous Delivery |
CI |
Continuous Integration |
ISTQB |
International Software Testing Qualifications Board |
ICD |
Interface Control Document |
PI |
Program Increment (SAFe context) |
PO |
Product Owner |
SAFe |
Scaled Agile Framework |
SKA |
Square Kilometre Array |
SKAO |
SKA Organisation |
SUT |
System Under Test |
TDD |
Test Driven Development |
In a nutshell
Important
This is a quick summary of the do’s and don’t do’s entailed by this document.
For developers and teams
Each team should have a role responsible for the quality of the tests delivered by the team.
All developers within a team are responsible for creating tests.
The only source of truth are the tests running in the CI pipeline. “It works for me” is a no go.
Pay attention to code coverage: in code reviews you should be able to defend why the parts not covered by tests are not creating a significant risk.
Unit, component, integration and system-level tests are all needed.
Relentlessly improve the quality of testware: we need to rely on it.
Each team (typically via the role above) must work with the Testing CoP to increase the quality level of the whole codebase by sharing experiences and developing new standards.
Practice a test-first/TDD/BDD approach: first the tests, then the production code.
Malfunctions in testware are high priority fixes to do.
For Product/Feature/Capability Owners
Each feature/capability must have at least 1 acceptance test expressed in an appropriate, comprehensible way that is possibly automated (ideally with a BDD/Gherkin test).
Product/feature/enabler/capability owners must ensure testing reflects the requirements of the feature/enabler/capability.
Bugs are always logged in some backlog (team backlog, global one, SKAMPI).
Introduction
What follows is the software testing policy and strategy produced by the Testing Community of Practice. This document is specific for software development, it explicitly excludes all sorts of verification and validation activities performed by AIV (Assembly, Integration and Verification) teams.
This is version 1.3.0 of this document, completed on 2022-07-15.
Purpose of the document
The purpose of this document is to specify the testing policy and strategy for SKA software; the policy answers the question “why should we test?”, and the strategy answers “how do we implement the policy?”.
The policy should achieve alignment between all stakeholders regarding the expected benefit of testing. The strategy should help developers and testers to establish a testing process.
Important
On the notion of “requirement”
In this document we use the term “requirement” to mean any combination of descriptions of user needs or software component properties like user story, feature, enabler, use case, architectural specifications, interface specifications, or other non-functional qualities (eg. desired performance levels).
This is different, and more general, than the meaning that Systems Engineering assigns to “requirement”, which refers only to formally agreed level 1, level2, level 3, ICD and verification requirements of the telescopes.
Applicable documents
The following documents are applicable to the extent stated herein. In the event of conflict between the contents of the applicable documents and this document, the applicable documents shall take precedence.
SKA-TEL-SKO-0000661 - Fundamental SKA Software and Hardware Description Language Standards
SKA-TEL-SKO-0001201 - ENGINEERING MANAGEMENT PLAN
Reference documents
International Software Testing Qualification Board - Glossary https://glossary.istqb.org
See other referenced material at the end of the document.
Key definitions
When dealing with software testing, many terms are defined differently in different contexts. It is important to standardise the vocabulary used by SKA1 in this specific domain according to the following definitions, mostly derived from ISTQB Glossary.
- Testing
The process consisting of all lifecycle activities, both static and dynamic, concerned with planning, preparation and evaluation of software products and related work products to determine that they satisfy specified requirements, to demonstrate that they are fit for purpose and to detect bugs.
- Debugging
The process of finding, analyzing and removing the causes of failures in software.
Note
The purpose of defining both “testing” and “debugging” is so that readers get rid of the idea that one does testing while they are doing debugging. They are two distinct activities.
- Bug
A flaw in a component or system that can cause the component or system to fail to perform its required function, e.g. an incorrect statement or data definition. Synonyms: defect, fault.
- Failure/Symptom
Deviation of the component or system from its expected delivery, service or result.
- Error
A human action that produces an incorrect result (including inserting a bug in the code or writing the wrong specification).
- Test Case
A test case is a set of preconditions, inputs, actions (where applicable), expected results, and postconditions, developed based on test conditions. Please, note the difference with “Test script”. See also “Test Condition”.
- Test Script
A test script is an implementation of a “Test Case” in a particular programming language and test automation framework. Please, note the difference with “Test Case”. See also “Test Condition”.
- Test Condition
A testable aspect of a component or system identified as a basis for testing. More informally, a test condition expresses how the SUT will be exercised and how it will be verified.
- Fitness for use
Said for a product or service that meets the needs of those who will actually use them. Often used as a synonym of “quality in use” (the extent to which a product used by specific users meets their needs to achieve specific goals with effectiveness, productivity, safety and satisfaction in specific contexts of use [ISO/IEC 25000]).
- Component
Here the word “component” refers to deployment units, rather than software modules or other static structures. Components can be binary artefacts such as jar, DLL or wheel files, and their “containers” like threads, processes, services, Docker containers or virtual machines.
Testing levels refer to the granularity of the system-under-test (SUT):
- Unit testing
The testing of individual software units (individual or clusters of functions, classes, methods, modules) that can be tested in isolation. In a stricter sense it means testing methods or functions in such a way that the filesystem, the network, the database are not involved. Usually these tests are fast (i.e. an execution of an entire test set provides feedback to the programmer in a matter of seconds; each test case runs for a few milliseconds). Normally the unit under test is run in an environment that is totally under control of the developer. For SKA this means and unit tests must always run locally (and pass).
- Component testing
Component testing aims at exposing defects of a particular component when run in an environment where other components or services are available, either production ones or test doubles.
- Integration testing
Testing performed to expose defects in the interfaces and in the interaction between components or subsystems. In a strict sense this level applies only to testing the interface between 2+ components; in a wider sense and in the context of an incremental process, it means testing that covers a cluster of integrated components.
The SUT consists of 2 or more components, and it is run in an environment where components or services external to the SUT include production ones and test doubles. The specific configuration of the SUT should include this information and should be clearly represented. Integration testing may also include hardware-software integration testing, which is performed to expose defects in the interfaces and interaction between hardware and software components.
- System testing
Testing an integrated system to verify that it meets specified requirements. In system testing the SUT includes production and possibly simulated or emulated components and is run in an environment where external services/systems can be interacted with. The specific configuration of the SUT should include this information and should be clearly represented.
Other useful definitions are:
- Test basis
All artefacts from which the requirements of a unit, module, component or system can be inferred and the artefacts on which the test cases are based. For example, the source code, a list of use cases, a set of partitions of a data domain, a set of configurations.
- Confirmation testing
Testing performed when handling a defect. Done before fixing it in order to replicate and characterise the failure. Done after fixing to make sure that the defect has been removed.
- Regression testing
Testing of a previously tested program following its modification to ensure that defects have not been introduced or uncovered in unchanged areas of the software, as a result of the changes made. It is performed when the software or its environment is changed.
- Exploratory testing
An informal test design technique where the tester actively designs the tests as those tests are performed and uses information gained while testing to design new and better tests. It consists of simultaneous exploration of the system and checking that what it does is suitable for the intended use.
- End-to-end (e2e) tests
These are system, acceptance or component tests that use as observation and control points an API whose entry points are all at the same abstraction level, and tests exercise all or most of the components of the SUT. End-to-end tests are different from other system tests; examples of non-e2e tests are tests that control the SUT from a high level interface and observe some of its components through a lower-level, component-specific, interface.
- Acceptance testing
Formal testing with respect to user needs, requirements (in the wider sense), and business processes conducted to determine whether or not a system satisfies the acceptance criteria and to enable the user, customers or other authorised entity to determine whether or not to accept the system.
- Stub object
In the context of unit testing, we replace a real object with a test-specific object that feeds the desired indirect inputs into the SUT.
- Mock object
In the context of unit testing, we replace an object the SUT depends on with a test-specific object that verifies it is being used correctly by the SUT.
- Fake object
In the context of unit testing, we replace a component that the SUT depends on with a much lighter-weight implementation.
- Test double
We replace a part (object, module or component) on which the SUT depends with a “test-specific equivalent’’, which could be a stub, mock, fake, simulated or emulated part. This notion applies to unit, integration and to a smaller extent to system tests as well, where we do not expect the use of fake/stub components.
- Production component
In the context of integration and system testing, a production component is the one used in production.
- Fake component
In the context of integration testing, a fake component replaces a real one that the SUT depends on and which is based on a much lighter-weight implementation.
- Stub component
In the context of integration testing, a stub component replaces a production one and feeds the desired indirect inputs into the SUT.
- Emulated component
A device, computer program, or system that accepts the same inputs and produces the same outputs as a given system. In the context of integration and system testing, an emulated component is developed to provide part of the external behaviour expected by the component it replaces. Compared to a fake component, the emulator is based on a heavier implementation effort and provides a much more complex behaviour. Compared to a simulator, the emulator makes no attempts to represent the internals of the emulated component. Emulators can be developed for hardware or software components.
- Simulated component
A device, computer program or system used during testing, which behaves or operates like a given system when provided with a set of controlled inputs. In the context of integration and system testing, a simulated component is developed to provide part of the behaviour expected by the component it replaces. Compared to a fake component, the simulator is based on a heavier implementation effort and provides a much more complex behaviour. Simulators can be developed for hardware or software components.
Testing Policy
This policy and this strategy apply exclusively to software-only SKA artefacts that are developed by teams working within the SAFe framework. As mentioned above this policy does not cover verification and validation activities involving hardware components and the telescope systems.
Each team is expected to comply with the policy and to adopt the strategy described here, or define and publish a more specific strategy in cases this one is not suitable.
Goals of testing
There are three overarching goals that we want to achieve.
Goal 1: to establish a testing process that supports development teams.
Goal 2: to establish a testing process that assesses functionality and fitness for use of the product that will be used by AIV engineers and commissioners.
Goal 3: to establish a testing process that can support project management
Goal 1: Supporting the development teams
With reference to the test quadrants (Figure 1), this goal focusses on the 3rd quadrant, on the bottom left of the picture: tests that are technology facing.
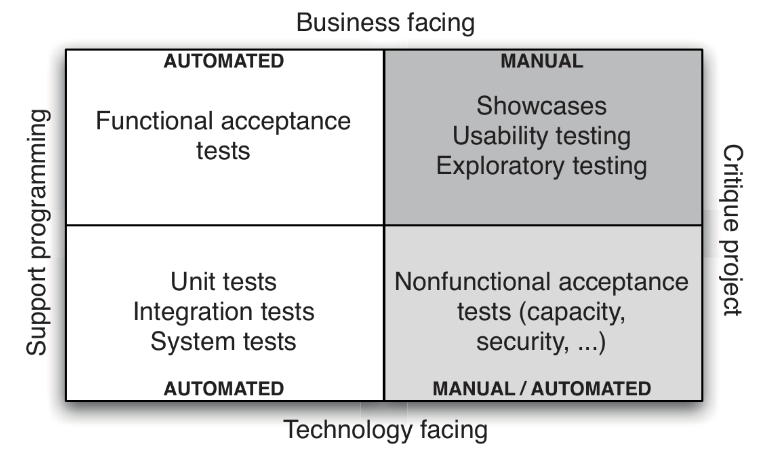
Figure 1: Test quadrants, picture taken from (Humble and Farley, Continuous Delivery, 2011).
The expected results of achieving this goal are that effective technical practices are performed regularly by each team (eg. TDD, test-first, test automation).
The testing process that will be established should help create testable software products, it should lead to a well-designed test automation architecture, it should push teams to practise TDD, test-first, and adopt suitable test automation patterns.
Expected outcomes are that once testable systems are produced, a relatively large number of unit tests will be automated, new tests will be regularly developed within sprints, refactorings will be “protected” by automated tests, and bug fixes will be confirmed by specific automated tests, teams will be empowered and become efficient in developing high quality code. More specifically:
team members explore different test automation frameworks and learn how to use them efficiently;
team members learn how to implement tests via techniques like test driven development and test-first, how to use test doubles, how to monitor code coverage levels, how to do pair programming and code reviews;
as an effect of adopting some of those techniques, teams reduce technical debt or keep it at bay; therefore they become more and more efficient in code refactoring and in writing high quality code;
they will become more proficient in increasing quality of the testing system, so that it becomes easily maintainable;
by adopting some of those techniques, teams will develop systems that are more and more testable; this will increase modularity, extendability and understandability of the system, hence its quality;
team members become used to developing automated tests within the same sprint during which the tested code is written;
reliance on automated tests will reduce the time needed for test execution and enable regression testing to be performed several times during a sprint (or even a day). Stability of the delivered artefacts will improve.
Goal 2: Adequate functionality and fitness for use
With respect to the above quadrants, this goal focuses on quadrants 1 and 2 (top row), covering quality attributes dealing with functional adequacy and fitness for use. The context of use of the products are the ITF and AA0.5, where the system will be mostly used by AIV engineers, maintenance engineers and commissioners (the “customers”). By “requirement” we mean the wider sense: any combination of user stories, features, enablers, use cases, formally agreed interfaces, system and subsystem requirements.
Note
At the moment (June 2022) it looks like the ITF has no defined verification requirements. Those that exist refer to the AA0.5. Also, consider that there are other test environments that are being used, but not for this goal.
We expect that the following outcomes will be achieved:
delivered software components will correctly implement interfaces and contracts derived from agreed features and interface specifications;
software components can be run both on simulated platforms or on dedicated hardware components; delivered software components can be integrated into a system that exhibits the desired behaviour, and that is testable (hence observable and controllable);
bugs in integrated components can be quickly diagnosed, fixed and regression unit, component, integration, system tests can be easily re-run behaviour-driven-development (BDD) is promoted as a way to early-on negotiate and agree on requirements (wider sense) and drive development;
the needs of the customers are adequately captured and addressed by the delivered components.
Goal 3: Supporting project management
We want a testing process that can inform program management (content authorities, architects, process and systems engineers) regarding how the development process is proceeding and the actual quality level of the delivered software.
Thus:
traceability of test results to all sorts of requirements is needed, and vice versa. In this way we can provide traceability of tests to requirements, and easily determine what is the degree of satisfaction of certain requirements based on test results.
Functional and non-functional completeness of specific requirements could also be assessed by test results.
Integration of components during each PI should provide status information about what works and what does not yet work, and that should be based on automated tests being routinely run. These test reports are the basis to assess progress during each PI.
Component and system tests should be used to establish a living documentation, that is the usage of test cases and specifications by example as a documentation of the business logic and policies actually implemented by the tested system.
Bug management provides metrics that can also be used to assess the quality of software components.
Monitoring implementation of the policy
Adoption of this policy needs to be monitored in a lightweight fashion. We suggest that each team regularly (such as at each sprint) reports the following (possibly in an automatic way):
total number of defined test cases, split by test level (unit, component, integration/system tests);number of logged open bugs;
age of logged open bugs;
number of test cases that are labelled as “unstable” or that are skipped, and for how long they are in such a state
for unit tests, code coverage (the “execution branch/decision coverage” criterion is what we would like to monitor, for code that was written by the team);
for integration and system tests report the percentages of requirements (in the wider sense) that are covered by existing tests, and the percentage of tests that fail.
These metrics should be automatically computed and updated, and made available to every stakeholder in SKA.
Testing strategy
A testing strategy describes how the test policy is implemented and it should help each team member to better understand what kind of test to write, how many and how to write them. This testing strategy refers to the testing policy described above.
Because of the diversity of SKA development teams and the diversity of the nature of the systems that they work upon (ranging from web-based UIs to embedded systems), we suggest a testing strategy that is likely to be suitable for most teams and let each team decide if a refined strategy is needed. In this case each team should explicitly define such a modified strategy, it should be compatible with this one, it should support the policy and it should be made public.
Scope, roles and responsibilities
This strategy applies to all the software that is being developed within the SKA.
Unit tests
Programmers adopt a TDD, BDD or test-first approach and almost all unit tests are developed before production code on the basis of technical specifications or intended meaning of the new code. Testers can assist programmers in defining good test cases.
In addition, when beginning to fix a bug, programmers, possibly with the tester, define one or more unit tests that confirm that bug. This is done prior to fixing the bug.
For unit testing, code coverage figures should be monitored, especially branch/condition coverage (as opposed to statement coverage). In particular the tester should analyse what part of the code is not being covered by tests, assess how important those fragments are, and decide if they are worth being covered. If so, new tests should be designed. If not the team should be able to defend why the parts not covered by tests are deemed not being risky. These risks need to be discussed during code reviews.
Risks should be assessed in terms of possible failures and their impact on the project: reduction of value of the system, difficulty in diagnosing failures, delays in deployment, damage to stored data, malfunctions to other components, impact on users.
Component tests
The product owner in collaboration with a tester and/or a programmer defines the acceptance criteria of a user story and on this basis the tester with the assistance of programmers designs and implements (unit and) component tests. All these tests are automated, possibly during the same sprint in which the user story is being developed.
Owners of features/enablers define the corresponding acceptance criteria; these are negotiated with the teams and then used by team members to define corresponding component tests. These tests are defined prior to the development of the feature/enabler, in a test-first, possibly BDD fashion. In this way team(s) working on the feature/enabler will be able to check when their code passes the acceptance criteria.
Each feature/enabler should be covered by at least one component test, possibly written in Gherkin. In general it is the Feature Owner’s call to decide which component tests need to be written in Gherkin. The decision criterion is based on who are the stakeholders of the tests: if they are developers, then Gherkin is probably not needed. If they are non-developers (eg. management, astronomers, architects) then Gherkin might be useful. Product owners and feature owners decide if a component test should be stored in Jira/Xray and if the test should be linked to the feature/enabler.
Tests written in Gherkin contribute to the living documentation and follow the “Specification by example” approach. Therefore attention should be given to how scenarios and steps are formulated, what parameters are used to implement examples, how many and what examples are used to “explain” the scenario. Attention is needed also to make steps as reusable as appropriate.
Integration and system tests
System tests are defined by the AIV Software Support teams, who negotiate them with feature owners and architects. They are derived from acceptance criteria of epics, capabilities or features/enablers. Some tests are also derived from happy and sad paths of use cases: each happy path should be covered by 1+ integration/system test. Integration tests can be derived from interface specifications and Architecture Design Records and Architecture Design Documents. Product Owners in collaboration with the development teams define the integration tests verifying the interface between the component being developed and a third party.
System tests should also be linked for traceability purposes to requirements (in the wider sense). They should also be present in Jira and formulated in Gherkin. The call is on the feature owner and the AIV teams to decide when this is appropriate. Tests written in Gherkin contribute to the living documentation (as described above for component tests).
Automation and implementation of system tests is the responsibility of team members. Feature owners are expected to identify the teams who should implement those tests. Development teams are also in charge of developing and maintaining test doubles that can be needed for integration testing.
Acceptance tests
Acceptance testing happens at different levels and stages of qualification, and possibly with slightly different workflows for different products.
The suite of tests executed for acceptance of a single component is identified by the Product Owner in collaboration with the development team. These tests are captured in a test plan in Jira, and when executed in the Continuous Integration environment in the cloud. They provide rationale and justification for Factory Acceptance Testing. It is important that these tests include the necessary integration and functional tests to provide evidence of verification of requirements and interfaces, via the traceability mechanisms described above. The AIV Software Support teams review the test plan for acceptance, and collaborate with the development team in defining additional tests where required.
Acceptance testing in the System ITF and for site acceptance testing (SAT) qualification environments is managed by AIV Software Support teams with the support of the development teams. This activity aligns with the system AIV integration plans and schedules, and it will make use of the automated tests described above.
Where such an activity will involve execution of test procedures that are not automated or not developed in other stages of the verification process, it will be AIV Software Support to make sure that these are correctly captured and where necessary inform the feature development activity, supported by the Product Managers and Product Owners.
Where a contractor is responsible for integration of multiple components in a Prototype System Integration (PSI) facility, the integration contractor will act on behalf of the AIV teams at the appropriate level of integration, with the same functions.
Test environment
In the future there will be specialised test environments in the ITFs and the AA0.5. In the Developer’s portal there is a description of how test environments can be provisioned: see Testing Skampi.
There is a staging environment, currently used only by the Skampi codebase.
How Pipeline Machinery can be used for test automation: https://developer.skao.int/en/latest/tools/ci-cd/skao-pipeline-machinery-tutorial.html
How to test setup and test SKAMPI:
How to set up a short living shared environment on STFC:
Test data
Test data, or reference to them when more appropriate, are to be stored as resource files that can be accessed and used by test cases. When applicable, test data should be versioned.
Test automation
Different projects have different needs. What follows is a non-exhaustive list of test automation frameworks and support libraries:
for developers using Python: pytest, pytest-bdd, assertpy, mock, tox
for developers using Javascript: Jest
for testers that have to develop end-to-end tests: Selenium, Cypress
for developers using C or C++: googletest
Developing unit/module/integration tests for Tango devices might be particularly challenging. So far, teams have devised creative ways to use mocks in Python to cope with the problem: https://confluence.skatelescope.org/display/SE/How+to+use+mocks+with+Tango.
There is also a reliable library to support testing asynchronous behaviour in Tango devices: see https://gitlab.com/ska-telescope/ska-tango-testing and an associated presentation.
Another important approach to write unit/module tests in a way that they don’t depend on the Tango infrastructure is to apply the Humble Object design pattern, that is extracting the domain logic from Tango-related code and move it to a separate python object that can be tested in isolation from Tango. See some preliminary examples in https://confluence.skatelescope.org/x/MA0xBQ.
Other routes have been followed to implement system-level tests using Gherkin: https://confluence.skatelescope.org/display/SE/How+to+implement+BDD+tests. See also the BDD guide in the Developer Portal: https://developer.skatelescope.org/en/latest/tools/bdd-test-context.html and https://developer.skatelescope.org/en/latest/tools/bdd-walkthrough.html.
See additional details on Pytest configuration.
In any case attention should be paid to the quality of the testware: code of the test cases, code of assertions and fixtures, code for data handling, code implementing tools used for testing. We need to trust our tests, and we need to spend as little effort as possible maintaining them. Pay attention to messages in test assertions: they are the user interface of tests. They should be informative as to what has happened.
The important thing is that tests should clearly convey the intention: what do they do. Details regarding “how they work” should be hidden inside appropriate abstraction layers (auxiliary fixtures, methods, classes, variables, configurations). In this way tests can be used as a source of documentation (written in a programming language rather than plain English) which is extremely useful for integration testing. However, for complex tests, some commenting may still be useful to guide subsequent test maintainers.
Continuous integration
How the CICD pipeline is organized and how it should be used is described in https://developer.skao.int/projects/skampi/en/latest/testing.html#pipeline-stages-for-testing.
It is important that teams, when configuring their own CICD pipeline, make sure that the testing stage creates and stores important artefacts related to testing. See our documentation on CI-CD.
System and integration tests that are applied to the systems running in the staging environment can be classified as quarantined.
Quarantined tests are such that:
they are allowed to fail without breaking the CI pipeline;
such tests should be run any time a pipeline is triggered;
they should provide the usual pass/fail/error outcome;
they should include their output into the xml/json report files;
the CI engine might send an email to the developer who triggered the pipeline if one of such tests fails.
The purpose of marking a test as “quarantined” is to avoid blocking the pipeline in case of a test that is flaky. Tests should be quarantined only in feature branches. Such tests need to be fixed as soon as possible, however. And that is the reason why they should be executed all the time.
A release manager is expected to make the decision as to which test to put into quarantine, and when to move it back as a normal regression test or to get rid of it.
Confirmation and regression testing
Regression testing is performed at least every time code is committed on any branch in the source code repository. This should be ensured by the CI/DI pipeline.
In order to implement an effective CI/CD pipeline, automated test cases should be classified also (in addition to belonging to one or more test sets) in terms of their speed of execution, like “fast”, “medium”, “slow”. In this way a programmer that wants a quick feedback (less than 1 minute) would run only the fast tests, the same programmer that is about to commit/push their code at the end of the day might want to run fast and medium tests and be willing to wait some 10 minutes to get feedback, and finally a programmer ready to merge a branch into master might want to run all tests, and be willing to wait half an hour or more.
Manual and automatic tests
We expect that the vast majority of the tests will be automatic. However some tests can, and in some cases they should, be manual.
Tests that are to be used seldomly, definitely not as regression tests, might not be implemented as automatic scripts because of their poor cost/benefit value.
Tests that have to involve manual steps (like turning on a piece of hardware) for which it would be too difficult to implement such actions via software could be manual or hybrid tests. A hybrid test is a test where part of the execution is automatic (like preparation of data), alternated with operations that have to be manual. We suggest that most of the tests to be used in regression testing become 100% automatic.
Exploratory testing is inherently a highly creative and therefore manual activity.
Bug management
For the overall SKA approach to Bug Management please refer to Reporting Bugs. While that section concentrates on system-level bugs much of what is described also applies to “team-level” bugs. Some key guidelines for team-level bugs are:
Bugs found by the team during a sprint for code developed are fixed on the fly during the same sprint, with no logging at all. If they cannot be fixed on the fly, soon after they are found they are logged on the team backlog.
Bugs that are found by the team during a sprint but that are related to changes made in previous sprints, are always logged on the team backlog (this is useful for measuring the quality of the testing process, with a metric called defect-detection-rate).
Team-level bugs that are reported by third parties (eg. non SKA and SKA users, other teams, product managers) are always logged, by whoever can do it. These bugs have to undergo a triage stage to confirm that they are a bug and find the team that is most appropriate to deal with them. At that point the bugs appear in the chosen team’s backlog. When resolved, appropriate comments and workflow state are updated in the team’s backlog and original reporter is notified as well, who may decide to close the bug, to keep it open, or to change it.
We require that each bug, when dealt with, has at least an automated (unit, integration, system, BDD) test replicating its failure. Such tests should be included in regression testing and should be used to demonstrate that the bug has been eventually fixed (confirmation test). There can be explicitly motivated exceptions to this rule, in cases where the cost of doing so would be prohibitive or simply not worthwhile.
We recommend that a test first approach is followed: confirmation tests are written before fixing the bug so that the failure can be demonstrated. The same test(s) can then be run after fixing it to demonstrate that the bug has been removed.
Logging occurs in JIRA by adding a new issue of type Bug to the product backlog and prioritized by the Product Owner in the same way other story/enabler/spike work is managed. The issue type Defect should not be used, as it is meant to indicate a deviation from SKA requirements.
For system-wide bugs please refer to Reporting Bugs.
General references
Relevant “How To Pages” are:
Relevant textbooks include:
Managing the Testing Process: Practical Tools and Techniques for Managing Hardware and Software Testing, R. Black, John Wiley & Sons Inc, 2009.
Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation, J. Humble and D. Farley, Addison-Wesley Professional, 2010.
xUnit Test Patterns: Refactoring Test Code, G. Meszaros, Addison-Wesley Professional, 2007.
Test Driven Development. By Example, Addison-Wesley Professional, K. Beck, 2002.
Agile Testing: A Practical Guide for Testers and Agile Teams, L. Crispin, Addison-Wesley Professional, 2008.
Growing Object-Oriented Software Guided by Tests, S. Freeman and N. Pryce, Addison-Wesley Professional, 2009.
Specification by Example: How Successful Teams Deliver the Right Software, G. Adzic, Manning; 1st edition, 2011.